Should You Send a CPU to Do a GPU’s Job?

At its Data-Centric Innovation Day in April 2019, Intel unveiled the new 2nd Generation Intel Xeon Scalable Processors (formerly Cascade Lake). The parts divide across the Platinum, Gold, Silver, and Bronze lines. At the top of the line is the Platinum 9200, also known as Advanced Performance (AP). The 9282 has 56 cores per processor in a multichip module (two dies in one package, resulting in double the core count and double the memory). Measuring 76.0 × 72.5 mm, it’s Intel’s largest package to date. Focusing on density, high-performance computing, and advanced analytics, this packaged server can only be purchased from OEMs who buy from Intel and make modifications.
One of the new features of the second-generation Xeon processors is Intel Deep Learning Boost (Intel DL Boost), also known as the Vector Neural Network Instruction (VNNI). VNNI combines three instructions into a single instruction, resulting in better use of computational resources and cache, while reducing the likelihood of bandwidth bottlenecks. Secondly, VNNI enables INT8 deep-learning inference, which boosts performance with “little loss of accuracy.” The 8-bit inference yields a theoretical peak compute gain of 4X over the 32-bit floating-point (FP32) operations.
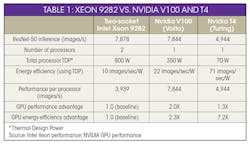
Fast-forward to May 13, 2019, when Intel announced that its new high-end CPU outperforms Nvidia’s GPU on ResNet-50, a popular convolutional neural network (CNN) for computer vision. Quoting Intel, “Today, we have achieved leadership performance of 7878 images per second on ResNet-50 with our latest generation of Intel Xeon Scalable processors, outperforming 7844 images per second on Nvidia Tesla V100, the best GPU performance as published by Nvidia on its website including T4.”
Employing the Xeon Platinum 9292, Intel achieved 7878 images/s by creating 28 virtual instances of four CPU cores each (using a batch size of 11) (Table 1). An open-source deep learning framework, Intel Optimized Caffe, was used to optimize the ResNet-50 code. Intel recently added four general optimizations for the new INT8 inference: activation memory optimization, weight sharing, convolution algorithm tuning, and first convolution transformation.
Nvidia wasted no time in replying to Intel’s performance claims, releasing the statement, “It’s not every day that one of the world’s leading tech companies highlights the benefits of your products. Intel did just that last week, comparing the inference performance of two of their most expensive CPUs to Nvidia GPUs.” Nvidia’s detailed reply was a dual-prong response centering on power efficiency and performance per processor.
The 9282 and V100 and T4
To better understand these claims and counterclaims, it’s useful to first step back and take a quick review of the V100 and the T4. Supporting a memory bandwidth of 9000 GB/s, the Nvidia V100 has 640 Tensor cores plus 5120 CUDA cores with 16 GB HBM2. The V100’s specified performance is 7.8 TFLOPS of double-precision performance and 125 TFLOPS of Tensor performance.
The next-generation Tesla T4 boasts 320 Turing Tensor cores and 2560 CUDA cores with 16 GB GDDR6 memory for peak 8.1 TLFOPS of double precision. First introduced as part of the Volta architecture, Tensor cores are extremely efficient at mixed precision computation.
In its response, Nvidia points out that, since there are actually two processors in a single Intel package, the comparison measurement should be on a per processor basis. This approach effectively halves Intel’s inference score. Intel’s own benchmark description—28 virtual instances multiplied by four cores equals 112 cores—confirms that Intel was using both processors on the multi-chip die.
Second, Intel’s performance numbers are achievable only when ResNet-50 was written with Caffe, and then optimized by Intel’s Optimization for Caffe. Nvidia’s TensorRT platform, which is able to take input from most all of the popular frameworks, including PyTorch, MxNet, TensorFlow, and Caffe, was used to create the deep-learning inference applications used in its benchmarks.
Third, Intel used 8-bit integer precision, whereas Nvidia used a mixture of 16- and 32-bit floating point. Next, while the Platinum 9282 has just been announced and is unavailable to most customers, the V100 was introduced back in 2017, and the T4 in 2018.
Finally, there’s the issue of price. Current estimates for just one of the Xeon’s 9282 processors range from $30,000 to $50,000. While on Amazon, you can score a V100 for $6,479 or a T4 card for $2,799. Even if you still view Intel’s dual socket as a single processing chip, the result of the comparison seems to be that Intel’s CPU barely wins on performance, but it requires a lot more cooling, power, and money.
Judging Benchmarks
In considering how to best compare these two platforms, another question comes to mind: Did Intel pick the best benchmark for comparison? One measure of complexity for AI models is the number of parameters. Released in 2015, by Microsoft Research Asia, ResNet-50 first successfully took the stage at the ImageNet competition that same year.
Bidirectional Encode Representation from Transformers (BERT) is an AI model released by Google in 2018 for natural language processing tasks, such as question answering. Compared to ResNet-50, which has 25 million parameters, BERT uses 340 million parameters—a 13X increase. Due to its additional complexity, Nvidia claims that using the BERT benchmark would provide a better test.
For this benchmark, notice that NVIDIA used a dual-socket Xeon Gold 6240 with 384 GB of RAM running at 2.6 GHz (Table 2). It was run with FP32 precision, inside an Intel TensorFlow (TF) Docker container. A batch size of four yielded the best CPU score, so the GPU used the same batch size. The GPU also used TensorFlow with automatic mixed precision enabled.
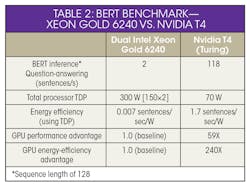
Some would argue that using the Xeon Gold 6420 with 18 cores instead of the Xeon Platinum 9282 isn’t exactly comparing apples to apples when considering the previous ResNet-50 test. The price and limited availability of Xeon 9282 may have helped determine why Nvidia didn’t use a Xeon Platinum 9282 for the test. Although this benchmark uses dual Xeon processors, Nvidia didn’t apply the “performance per processor” metric and didn’t compare the Xeon Gold to the powerhouse Volta 100. Perhaps these choices were also made to compensate for lack of access to a Xeon 9282.
Continuing to press the point that GPUs are better, Nvidia added a comparison of a recommender system known as Neural Collaborative Filtering (NCF) from the MLPerf training benchmark (Table 3). Used in applications such as those suggesting posts you might like on Facebook and Twitter, and recommending content for you on YouTube and Netflix, NCF utilizes the prior interaction of users to the offered items to formulate its recommendations.
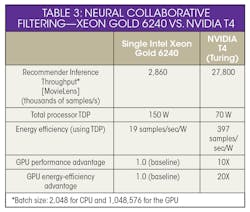
The systems used for these comparison tests were the same as used for the BERT benchmark. On the CPU, the Intel Benchmark for NCF on TensorFlow provided the benchmark results. The cynical might notice that this test only used one Xeon processor. Nvidia notes that the tests used a single-socket CPU configuration because it yields a better score than using dual processor.
The Bottom Line
While all of this competitive posturing is interesting, the real question is how do the results apply to our embedded military and aerospace arena? Included among the 50 new Intel SKUs are three “Gold” chips that support long lifecycles and better thermal performance: the 6238T (22 cores, 1.9 GHz, 125 TDP), 6230T (20 cores, 2.1 GHz, 125 TDP) and 5220T (18 cores, 2.2 GHZ, and 105 TDP). Fortunately, the Gold 6238T is very similar to the Gold 6240 that Nvidia used in its benchmarking.
Curtiss-Wright, in partnership with Wolf Advanced Technology, recently announced its new OpenVPX Turing products based on the TU104 GPU. The TU104 GPU is the foundation of Nvidia’s Quadro and Tesla products, including the Tesla T4 compared in the Nvidia benchmarks, and the Quadro RTX5000E featured in the VPX3-4935 3U and VPX6-4955 6U OpenVPX boards (see figure). The Tesla T4 has 2560 CUDA cores and 320 Tensor cores, while the RTX5000E boasts 3072 CUDA cores plus 384 Tensor cores. At 11.2 peak TFLOPS FP32, the RTX5000E improves on the performance of the T4 (8.1 TFLOPS).

Yes, with the introduction of the VNNI in its new processors, Intel has achieved up to a 14X improvement in inference performance over its first-generation Intel Xeon processors. Even Nvidia, conceded that “Intel’s latest Cascade Lake CPUs include new instructions that improve inference, making them the best CPUs for inference.”
However, NVIDIA further added that CPUs aren’t in the same league with Nvidia GPUs, which feature dedicated deep-learning-optimized Tensor cores. The benchmarks above back up this observation. Since GPUs were designed to perform parallel processing, it’s no surprise that they’re more efficient than CPUs in AI training and inference applications, due to the parallel nature of the processing. In the end, the Xeon CPUs are general-purpose processors that can do a decent job at inference if needed. Nvidia GPUs, though, which are designed to be the ideal solution for inference workloads, are faster and more energy-efficient for parallel workloads and AI applications.
Therefore, we can only conclude that the answer is no, you should not send a CPU to do a GPU’s job.
Tammy Carter is Senior Product Manager at Curtiss-Wright Defense Solutions.
